问题描述:
今天对接接口的时候,在解析对方的xml时,报了这样一个错误“Unicode(0xb) error-An invalid XML character (Unicode: 0xb) was found in the element content of the document.”
原因分析:
报错提示是说,xml中有一个非法的xml字符(Unicode: 0xb),unicode编码的0xb表示垂直tab( vertical tab,VT),在notepad++之类的文本编辑器中,显示为VT。详情见:https://en.wikipedia.org/wiki/Tab_key。
如有以下unicode编码后的文本:
%u63a5%u53d7%0b%u3002
unicdoe解码后,notepad++中的显示,可以看到VT字符:
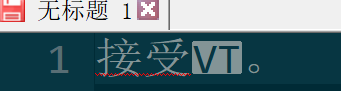
对于xml 1.0来说,它的合法的字符范围应该是(见:https://en.wikipedia.org/wiki/Valid_characters_in_XML#XML_1.0):
XML 1.0[edit]
Unicode code points in the following ranges are valid in XML 1.0 documents:[1]
- U+0009, U+000A, U+000D: these are the only C0 controls accepted in XML 1.0;
- U+0020–U+D7FF, U+E000–U+FFFD: this excludes some (not all) non-characters in the BMP (all surrogates, U+FFFE and U+FFFF are forbidden);
- U+10000–U+10FFFF: this includes all code points in supplementary planes, including non-characters.
The preceding code points ranges contain the following controls which are only valid in certain contexts in XML 1.0 documents, and whose usage is restricted and highly discouraged:
- U+007F–U+0084, U+0086–U+009F: this includes a C0 control character and all but one C1 control.
而0xb不在这个范围内,所以解析xml的时候会报错,解决的办法就是用正则将这些不合法的字符替换为空字符串,以此保证正常解析,java代码如下:
Pattern p = Pattern.compile("[^\\u0009\\u000A\\u000D\\u0020-\\uD7FF\\uE000-\\uFFFD\\u10000-\\u10FFFF]+");
requestXml = p.matcher(requestXml).replaceAll("");参考: